Scale Architecture
Every scale deployment has three logical roles. You always run exactly one main instance. Workers and API server replicas are optional and independently scalable.
The three roles
Main instance — synapseorchai/synapse-ai
The main instance is your existing Synapse install — the combined image that runs both the UI and the API server. In scale mode it takes on additional responsibilities:
- Accepts V2 API requests and enqueues jobs to Redis instead of executing them inline
- Syncs orchestration, agent, tool, and MCP server definitions from local JSON files to Postgres
- Opens Redis Stream reads and proxies step events to SSE clients in real time
- Hosts the Settings → Scale UI for configuring connections, viewing workers, inspecting runs, and managing the dead-letter queue
- Runs a heartbeat reaper that marks workers as
offlinewhen their heartbeats expire (>90 seconds since last heartbeat)
There is always exactly one main instance. It holds no exclusive locks — all coordination happens through Redis and Postgres.
Workers — synapseorchai/synapse-ai-worker
Workers are the execution tier. Each worker process:
- Connects to Redis and dequeues jobs via ARQ (Async Redis Queue)
- Reads orchestration and agent definitions from Postgres (not from local JSON files)
- Runs the
OrchestrationEngineto execute steps: LLM calls, tool invocations, MCP server requests, human steps - Publishes step events to Redis Streams as each step completes, making them available to SSE subscribers
- Registers itself in the
workersPostgres table on startup and sends a heartbeat every 30 seconds - Exposes a health endpoint on
port 9000—GET /healthreturns current status and active job count
Workers are stateless between jobs. Any worker can handle any job. Scale horizontally by starting more worker containers — all workers share the same Redis queue and Postgres database.
API server replicas — synapseorchai/synapse-ai-api-server
The API server image runs the FastAPI backend without the frontend UI. Use it when the API tier itself becomes a bottleneck:
- Identical V2 API surface as the main instance (enqueues jobs, reads Postgres, proxies SSE from Redis)
- No management UI — pair with a load balancer in front of the main instance and API replicas
- Stateless: any replica can serve any SSE stream for any run, at any time
Most deployments do not need dedicated API server replicas. The main instance handles API traffic well at low-to-medium load. Add API server replicas only when the main instance's API tier (not workers) becomes saturated.
Component diagram
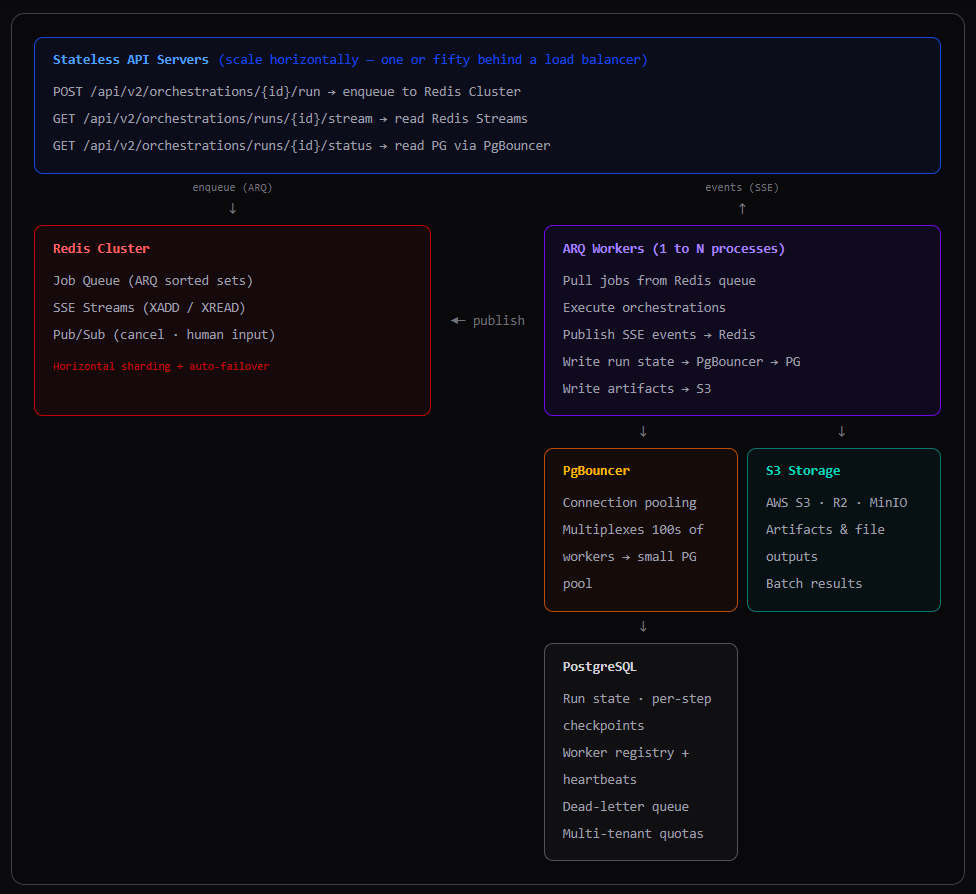
Redis
Redis serves as the coordination backbone. It carries five distinct types of data, each with its own key pattern.
1. Job queue (ARQ)
Workers dequeue jobs from Redis sorted sets. Each queue shard is a separate key.
synapse:orchestrations:{shard_id}
When the main instance receives a POST /api/v2/orchestrations/{id}/run, it calls arq_redis.enqueue_job("run_orchestration_job", ...), which writes to the sorted set with the current timestamp as the score. Workers run an ARQ consumer loop, dequeuing and executing jobs at up to WORKER_CONCURRENCY concurrent jobs per worker process.
With multiple queue shards (NUM_QUEUE_SHARDS > 1), jobs are distributed across synapse:orchestrations:0, synapse:orchestrations:1, etc. This is useful with Redis Cluster to spread load across cluster nodes.
2. Event streams (SSE delivery)
Each run gets its own Redis Stream. Workers write events as they execute each step. The main instance reads from the stream and forwards events to SSE-connected clients.
synapse:run:{run_id}:events
synapse:chat:{session_id}:events
Events are stored with a configurable TTL (PUBSUB_EVENT_TTL, default 1 hour). Clients that disconnect and reconnect can replay missed events by sending the Last-Event-ID header — the server replays all events after that stream ID. Up to 10,000 events per run are kept.
3. Worker heartbeats (pub/sub)
Workers publish a heartbeat message every 30 seconds. The main instance subscribes and uses this to detect newly-online workers and update the Workers panel.
synapse:workers:heartbeat
4. Cancellation signals
When a client calls POST /api/v2/orchestrations/runs/{run_id}/cancel, the main instance writes a cancellation key. The executing worker checks for this key at each step boundary and stops cleanly, updating the run status to cancelled.
synapse:cancel:{run_id}
Key exists = cancellation requested. Workers check at the start of each step, so cancellation latency equals the duration of the currently-executing step.
5. Human input buffer
When a run reaches a Human Step, the worker exits the ARQ job cleanly (job is marked done by ARQ) and publishes a paused sentinel. When the client submits a response via /resume, the main instance stores the response here before re-enqueueing the resume job.
synapse:human_input:{run_id}
Postgres
Workers read all definitions from Postgres and write all execution state here. The main instance syncs local definitions to Postgres via the Sync Now operation.
| Table | Written by | Read by | Contents |
|---|---|---|---|
orchestrations | Main (sync) | Workers, API | Full orchestration definitions — steps, routing, config (JSONB) |
agents | Main (sync) | Workers, API | Agent definitions — model, system prompt, tools, MCP servers |
tools | Main (sync) | Workers, API | Custom tool definitions — REST and Python tools |
mcp_servers | Main (sync) | Workers, API | MCP server configurations — transport, env, capabilities |
scale_settings | Main (sync) | Workers | LLM API keys and secret settings that workers need at execution time |
orchestration_runs | API (create), Workers (update) | API, UI | Run lifecycle state — status, current step, cost, tokens, timing |
chat_sessions | Workers | API, UI | Chat history per session |
workers | Workers (startup + heartbeat) | API, UI | Worker registry — status, active jobs, hostname, last heartbeat |
dead_letter_queue | Workers (on final failure) | UI | Jobs that exceeded max retries — inspectable and retriable from the UI |
Definitions are never written directly to Postgres from the UI. They always go through local JSON files first, then pushed to Postgres via Sync. This means the main instance is always the source of truth for definitions.
1. Client enqueues the run
POST /api/v2/orchestrations/{orch_id}/run
Authorization: Bearer sk-syn-...
Content-Type: application/json
{"message": "Write a competitive analysis of Redis vs Kafka"}
The main instance:
- Validates the API key and checks tenant quota (if tenant isolation is enabled)
- Generates a
run_id(format:run_{orch_id_prefix}_{timestamp_ms}) - Creates a row in
orchestration_runswithstatus = queued - Enqueues the job to Redis ARQ:
arq_redis.enqueue_job("run_orchestration_job", run_id=..., orch_id=...) - Returns immediately:
{
"run_id": "run_competitive_1780499750067",
"status": "queued",
"stream_url": "/api/v2/orchestrations/runs/run_competitive_1780499750067/stream",
"status_url": "/api/v2/orchestrations/runs/run_competitive_1780499750067/status"
}
2. Client subscribes to the SSE stream
GET /api/v2/orchestrations/runs/{run_id}/stream
Authorization: Bearer sk-syn-...
The main instance opens a read on Redis Stream synapse:run:{run_id}:events and begins yielding SSE lines. This connection stays open until the run completes or the client disconnects.
3. Worker picks up the job
An ARQ consumer dequeues the job from the Redis sorted set. The worker:
- Updates
orchestration_runs.status = runningin Postgres - Publishes the first event to the Redis Stream:
{"type": "worker_picked_up", "worker_id": "worker-prod-01", "timestamp": "2026-06-05T..."}
The client's SSE stream receives this within milliseconds.
4. Worker executes steps
For each step in the orchestration definition:
{"type": "step_start", "orch_step_id": "step_research", "step_name": "Research Topic", "step_type": "agent"}
{"type": "thinking", "content": "I'll use web search to find relevant information..."}
{"type": "tool_execution", "tool_name": "web_search", "args": {"query": "Redis vs Kafka comparison"}}
{"type": "tool_result", "tool_name": "web_search", "preview": "Redis is an in-memory data structure store..."}
{"type": "step_complete", "orch_step_id": "step_research", "duration_seconds": 8.2}
5. Run completes
The worker publishes the final events:
{"type": "orchestration_complete", "status": "completed", "final_state": {"analysis": "..."}}
{"type": "done"}
It then updates orchestration_runs in Postgres with status = completed, ended_at, total_cost_usd, and total_tokens_used. The main instance's SSE loop sees the done sentinel and closes the client connection cleanly.
6. Webhook delivery (optional)
If webhook_url was included in the run request, the worker POSTs the final result to that URL with an X-Synapse-Signature HMAC-SHA256 header for verification.
Human input — pause and resume
When an orchestration reaches a Human Step, execution suspends until a human provides input. The run does not time out.
1. Worker publishes the human input request event:
{
"type": "human_input_required",
"orch_step_id": "step_approve",
"prompt": "Please review the draft and decide whether to publish.",
"fields": [
{"name": "decision", "type": "select", "options": "approve,reject"},
{"name": "notes", "type": "text", "label": "Editor notes"}
]
}
2. Worker publishes {"type": "paused"} and exits the ARQ job cleanly (ARQ marks the job complete).
3. The SSE connection stays open — the client receives the paused event but does not close the connection.
Do not close the SSE connection when you receive {"type": "paused"}. It will automatically resume delivering events after the human responds. Only close when you receive {"type": "done"} or {"type": "stream_complete"}.
4. Human reviews the prompt and submits their response:
POST /api/v2/orchestrations/runs/{run_id}/resume
Authorization: Bearer sk-syn-...
Content-Type: application/json
{"response": {"decision": "approve", "notes": "Excellent — publish immediately."}}
5. The main instance stores the response in Redis at synapse:human_input:{run_id}.
6. A new ARQ job resume_orchestration_job is enqueued to Redis.
7. A worker (may be a different one than the original) picks up the resume job, restores the run checkpoint from Postgres, loads the human input from Redis, and continues execution from the step after the human step. The SSE stream resumes with new events.
Multiple human steps in the same orchestration repeat this cycle. The SSE connection stays open throughout.
Startup
When python worker_main.py executes:
- Reads
REDIS_URLandSCALE_POSTGRES_URLfrom environment variables - Starts a health HTTP server in a background thread on
WORKER_HEALTH_PORT(default: 9000) - Creates an async Postgres connection pool (
NullPoolifPGBOUNCER_MODE=1) - Reads LLM API keys from the
scale_settingsPostgres table - Connects to configured MCP servers (native Python and user-configured remote servers)
- Inserts a row into the
workerstable withstatus = online, its hostname, and health endpoint URL - Starts a background coroutine that sends a heartbeat every 30 seconds
- Starts the ARQ worker loop — begins consuming jobs from the configured queue shard
Job processing
Workers use asyncio for concurrency — up to WORKER_CONCURRENCY jobs run simultaneously within a single process as coroutines, not threads. This means:
- Blocking operations (synchronous I/O, CPU-heavy work) reduce effective concurrency — keep them in thread pools via
asyncio.to_thread - For I/O-heavy workloads (LLM API calls, web searches, database queries),
WORKER_CONCURRENCY=10to20per worker is a good starting point - For CPU-heavy workloads (local models, heavy data processing), keep concurrency lower and run more worker instances
An active_jobs counter is maintained in memory and reported in heartbeats and health checks.
Heartbeat
Every 30 seconds, each worker:
- Updates
workers.last_heartbeatandworkers.active_jobsin Postgres - Updates
workers.status(may transitiondraining → offlineafter shutdown) - Publishes a heartbeat message to Redis pub/sub channel
synapse:workers:heartbeat
The main instance runs a reaper coroutine that marks any worker as offline if its last heartbeat is older than 90 seconds. This covers crashed workers and network-partitioned instances.
Graceful shutdown
On SIGTERM (Docker stop, Kubernetes pod termination signal):
- The ARQ worker stops accepting new jobs from the queue
- Currently-running jobs continue executing until they complete
- The process waits up to
terminationGracePeriodSeconds(60 seconds in the k8s manifest) for in-flight jobs to finish - Updates
workers.status = offlinein Postgres - Publishes a final heartbeat
Jobs that cannot complete within the grace period remain in the ARQ queue with a queued state — another worker picks them up automatically on the next startup. This is transparent to the end client, who sees the SSE stream briefly pause then resume with a new worker_picked_up event.
Stateless API, stateful workers
The API tier (main instance and API server replicas) is stateless with respect to job execution. It holds no in-memory execution state. All run state lives in Postgres and Redis. This means:
- Any API server replica can serve any SSE stream for any run at any time
- Restarting the main instance does not interrupt in-flight runs — workers continue executing and publishing events; the SSE stream reconnects automatically
- Multiple API server replicas can be load-balanced without sticky sessions
Workers are stateful during job execution — they hold the in-memory execution context (step history, LLM conversation, shared state) for each active job. If a worker process crashes mid-run, the ARQ job entry has not been marked complete, so ARQ automatically requeues it when the next worker starts (subject to WORKER_MAX_RETRIES). After the final retry, the job moves to the dead-letter queue where it can be inspected and retried manually from the UI.
KEDA autoscaling
In Kubernetes, KEDA (Kubernetes Event Driven Autoscaling) watches the Redis ARQ queue depth and scales the worker Deployment automatically — no manual intervention needed.
The infra/k8s/worker-scaledobject.yaml manifest configures:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
spec:
scaleTargetRef:
name: synapse-worker
minReplicaCount: 1
maxReplicaCount: 100
cooldownPeriod: 60 # seconds before scaling down after queue drains
pollingInterval: 10 # seconds between queue depth checks
triggers:
- type: redis
metadata:
listName: synapse:orchestrations:default
listLength: "5" # add a new worker pod when > 5 jobs are queued per replica
When queue depth exceeds listLength × current_replicas, KEDA adds new worker pods immediately. When the queue drains, it scales back down to minReplicaCount after the cooldownPeriod.
The API tier uses a standard Kubernetes HorizontalPodAutoscaler that scales on CPU utilisation (70% target, 2–20 replicas). The API tier is I/O-bound (waiting on Redis and Postgres), so CPU-based scaling works correctly for it.